Blog
Retrieval Augmented Generation (RAG)

What is RAG?
LLMs are the most efficient and powerful models. The potential of LLMs has been demonstrated in a variety of activities. However, they experience hallucinations when it comes to answering domain-specific questions. Therefore, we require a single system that streamlines document extraction to answer generation and all the processes between them. We refer to this process as Retrieval Augmented Generation (RAG).
Why RAG?
LLM can learn new data in three ways: Training, Fine-tuning and Prompting. A model such as GPT-4 requires hundreds of millions of dollars to train. Both financially and in terms of time, fine-tuning is costly. Prompting for answers from text documents is effective, but these documents are often much larger than the context windows of Large Language Models (LLMs), posing a challenge.
This is addressed by Retrieval Augmented Generation (RAG) pipelines, which enable LLMs to respond to queries quickly by processing, storing, and retrieving relevant document sections.
How does RAG work?
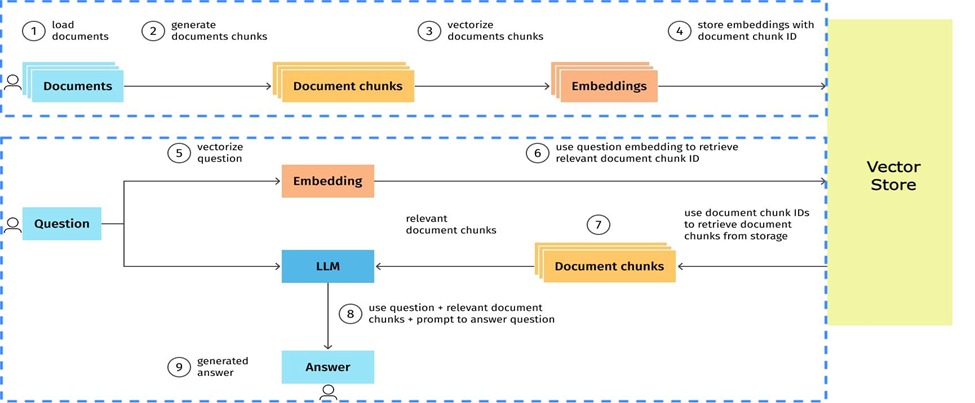
1.Document loading:As part of the data preparation for the document splitting, the first stage entails loading the documents from a data store, text extraction, parsing, formatting, and cleaning.
2.Document splitting:Next, documents are broken down into small manageable segments, or chunks. Strategies may range from fixed-size chunking to content-aware chunking, which understands the structure of the content and splits accordingly.
3.Text embedding: Next, these chunks are transformed into vector representations, or embeddings. This step is essential for the semantic comprehension of the document chunks.
4.Vector store:The created vectors are kept in a vector store, where each one is identified by a distinct document chunk ID. For quick and easy retrieval, the saved vectors are indexed here.
5.Query processing: When a query is received, it is also converted into a vector representation using the same technique as in the previous step.
6.Document retrieval: The Retriever, using the query's vector representation, locates and fetches the document chunks that are semantically most similar to the query. This retrieval is performed using similarity search techniques.
7.Document chunk fetching: The relevant document chunks are then retrieved from the original storage using their unique IDs.
8.LLM prompt creation self-executing agreements with the terms of the contract directly written into code. These contracts can automate a wide range of processes, from financial transactions to supply chain management, eliminating the need for intermediaries.
9.Answer generation: In the final step, the LLM generates a response based on the prompt, thus concluding the RAG process.